- 软件



/多国语言[中文]/

/简体/

/简体/

/多国语言[中文]/

/简体/

/简体/

/简体/

/简体/

/简体/

/简体/
 网易木木助手-网易木木模拟器下载 v2.7.13.200官方版
网易木木助手-网易木木模拟器下载 v2.7.13.200官方版 雷电模拟器安卓9-雷电模拟器安卓9.0下载 v9.0.33.0官方版
雷电模拟器安卓9-雷电模拟器安卓9.0下载 v9.0.33.0官方版 兆懿运行平台(移动应用运行平台)下载 v1.1.0官方版
兆懿运行平台(移动应用运行平台)下载 v1.1.0官方版 MuMu手游助手-MuMu手游助手下载 v1.5.0.6官方版
MuMu手游助手-MuMu手游助手下载 v1.5.0.6官方版 华为移动应用引擎电脑版-华为移动应用引擎下载 v1.2.1.1官方版
华为移动应用引擎电脑版-华为移动应用引擎下载 v1.2.1.1官方版 360安全卫士电脑版官方下载-360安全卫士下载 v13.0.0.2122官方版
360安全卫士电脑版官方下载-360安全卫士下载 v13.0.0.2122官方版 万能录屏大师-万能录屏大师下载 v1.0官方版
万能录屏大师-万能录屏大师下载 v1.0官方版 野葱录屏-野葱下载 v2.4.1473.249官方版
野葱录屏-野葱下载 v2.4.1473.249官方版 网红主播音效助手-网红主播音效助手下载 v5.2官方版
网红主播音效助手-网红主播音效助手下载 v5.2官方版 易谱软件下载-易谱ziipoo下载 v2.5.6.8官方版
易谱软件下载-易谱ziipoo下载 v2.5.6.8官方版软件Tags: 百度VS腾讯OCR图片批量识别转文字工具
百度VS腾讯OCR图片批量识别转文字是一款图片识别文字软件,软件通过接入百度与腾讯ocr识别接口,可以实现免费文字识别功能,可准确的对文字字体进行识别和段落切分。
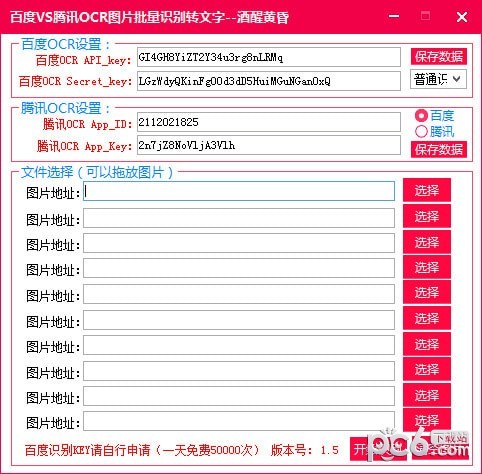
OCR软件主要是由下面几个部分组成。
图像输入、预处理:
图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有OpenCV,CxImage等开源项目 。预处理:主要包括二值化,噪声去除,倾斜较正等
二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去噪,就叫做噪声去除
倾斜较正:
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
版面分析:
将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
字符切割:
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能,这就需要文字识别软件有字符切割功能。
字符识别:
这一研究,已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
版面恢复:
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变,的输出到word文档,pdf文档等,这一过程就叫做版面恢复。
后处理、校对:
根据特定的语言上下文的关系,对识别结果进行较正,就是后处理。
使用方法百度OCR申请KEY教程
1、浏览器打开输入网址:https://cloud.baidu.com/ 后申请一个账号(申请是免费的不要钱)
2、点击创建应用 (创建应用 也是免费的 )
3、应用已经创建好了,里面就有 api_key 和Secret_Key 应用可以创建无数个随便你创建多少都可以,每个创建的密钥都不同
4、创建应用了,看看是否已开通了文字识别功能
5、以上都操作完毕就拿出你申请的 KEY 就可以使用了!
更新日志1.修正个别电脑识别只显示识别一张图的问题。
2.软件停止更新。
 雷电模拟器国际版-LDPlayer(雷电模拟器海外版)下载 v4.0.37官方版手机软件
雷电模拟器国际版-LDPlayer(雷电模拟器海外版)下载 v4.0.37官方版手机软件
 华为EC6110-T免拆刷机固件下载 v1.0免费版硬件检测
华为EC6110-T免拆刷机固件下载 v1.0免费版硬件检测
 咩播直播软件-咩播直播软件下载 v0.13.102官方版媒体其他
咩播直播软件-咩播直播软件下载 v0.13.102官方版媒体其他
 联想M7405D驱动下载-联想M7405D打印机驱动下载 v1.0官方版万能驱动
联想M7405D驱动下载-联想M7405D打印机驱动下载 v1.0官方版万能驱动
 Ghidra-Ghidra(反汇编工具)下载 v9.0.4中文版编程开发
Ghidra-Ghidra(反汇编工具)下载 v9.0.4中文版编程开发
 雷云2.0下载-雷蛇云驱动(Razer Synapse 2.0)下载 v2.21.24.34官方版万能驱动
雷云2.0下载-雷蛇云驱动(Razer Synapse 2.0)下载 v2.21.24.34官方版万能驱动
 Office2021官方下载免费完整版-Microsoft Office 2021正式版下载 16.0.14701.20262官方版办公软件
Office2021官方下载免费完整版-Microsoft Office 2021正式版下载 16.0.14701.20262官方版办公软件
 京瓷FS-C8520MFP驱动-京瓷FS-C8520MFP打印机驱动下载 v6.1.0826官方版万能驱动
京瓷FS-C8520MFP驱动-京瓷FS-C8520MFP打印机驱动下载 v6.1.0826官方版万能驱动
 柯尼卡美能达C7222驱动-柯尼卡美能达C7222驱动下载 v1.0官方版万能驱动
柯尼卡美能达C7222驱动-柯尼卡美能达C7222驱动下载 v1.0官方版万能驱动






